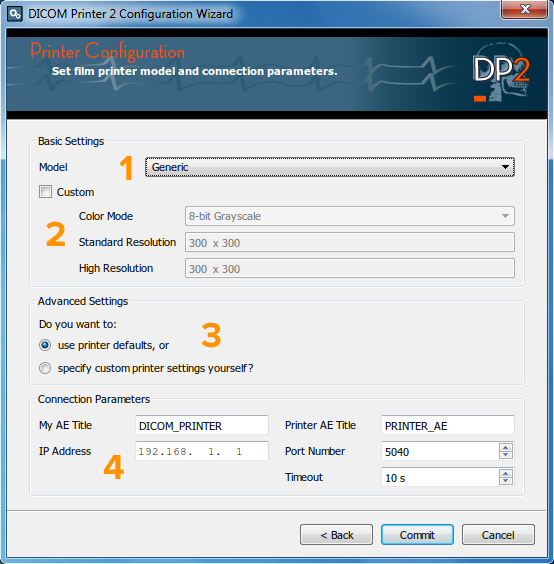
This article is intended for IT staff. It includes samples of XML files that might be difficult to understand for the non-initiated. If you would like to learn about automated DICOM storage without the technical jargon, please send us an email.
One of the consequences of implementing a PACS, is that everything has to be sent there. This has produced a world of patchwork solutions that often involve generating paper records for the sole purpose of digitizing them back into electronic form.
I truly can’t think of a greater offense to the purpose of electronic health records than to make them complicit in the needless use of paper. Not to mention the tragedy of entire human working lives spent scanning things that have just come out of a printer.
Attaching Paper to PACS
DICOM Printer 2 was originally designed to address this problem. The XML-based configuration, regular expression matching, plug-in interfaces and capability to operate according to data-driven logic gives it a natural ability to fit into whatever part of patient workflows are most wasteful of human time.
In this post, I go through a short example of a common configuration, broadly applicable to the following workflow:
- A document is generated; perhaps by a fax server, a medical instrument (such as BMD), or a staff member who transcribes a dictated report.
- The document is printed to paper.
- The document is prepared into a scanning batch, and scanned.
- Office staff open the scanned document and manually upload, link, or otherwise select a patient record to which it should be attached.
- The document arrives in PACS for permanent storage.
Any reasonable person can see that steps 2 and 3 are unnecessary, and step 4 often involves visual data searching that can quite often be automatically performed by a computer.
One of our most common configurations, results in the following workflow:
- A document is generated.
- DP2 automatically reads patient and study information from the contents.
- DP2 queries PACS and/or Worklist for the patient record, associates it, and,
- The document arrives in PACS.
No paper, no shameless waste of human life, still the same result in PACS. Here is the configuration that is needed to achieve this:
<DicomPrinterConfig>
...
<ActionsList>
<ParseJobTextFile name="ParseContents">
<DcmTag tag="(8,50)">^(.*)\-.*$</DcmTag>
<DcmTag tag="(8,60)">^.*\-(.*)$</DcmTag>
</ParseJobFileName>
<Query name="Query" type="Worklist">
<DcmTag tag="(0008,0050)" />
<DcmTag tag="(0008,0060)" />
<DcmTag tag="(0010,0020)" />
<DcmTag tag="(0020,000D)" />
<ConnectionParameters>
<MyAeTitle>DICOMPRINTER2</MyAeTitle>
<PeerAeTitle>DVT</PeerAeTitle>
<Host>localhost</Host>
<Port>104</Port>
</ConnectionParameters>
</Query>
<Store name="Store">
<Compression type="RLE" />
<ConnectionParameters>
<PeerAeTitle>CONQUESTSRV1</PeerAeTitle>
<Host>192.168.0.41</Host>
<Port>5678</Port>
</ConnectionParameters>
</Store>
</ActionsList>
<Workflow>
<Perform action="ParseContents" onError="Hold" />
<Perform action="Query" onError="Suspend" />
<If field="QUERY_FOUND" value="1">
<Statements>
<Perform action="Store" />
</Statements>
<Else>
<Suspend resumeAction="Query" />
</Else>
</If>
</Workflow>
</DicomPrinterConfig>
The parts of this file seem complex, but it is really comprised of only a few action definitions and a workflow that implements them.
The first action parses the contents of the printed document, looking for accession and modality values:
<ParseJobTextFile name="ParseContents">
<DcmTag tag="(8,50)">Accession: (.*)$</DcmTag>
<DcmTag tag="(8,60)">Modality: (.*)$</DcmTag>
</ParseJobFileName>
The two DcmTag elements describe regular expressions used to extract the values, and the tag attributes define where the data is to reside. The next action is:
<Query name="Query" type="Worklist">
<DcmTag tag="(0008,0050)" />
<DcmTag tag="(0008,0060)" />
<DcmTag tag="(0010,0020)" />
<DcmTag tag="(0020,000D)" />
<ConnectionParameters>
<MyAeTitle>DICOMPRINTER2</MyAeTitle>
<PeerAeTitle>DVT</PeerAeTitle>
<Host>localhost</Host>
<Port>104</Port>
</ConnectionParameters>
</Query>
Pretty self-explanatory: query worklist with accession and Modality, and retrieve Patient ID and Study UID. Note that if DICOM header attributes have previously been set in the workflow, then including them in a query automatically makes them part of the query parameters. In this case, because Accession and Modality will have already been extracted from the document, then the query would be based on these two parameters, and retrieve two more. The ConnectionParameters group is self-explanatory.
The next action stores the document to PACS:
<Store name="Store">
<Compression type="RLE" />
<ConnectionParameters>
<PeerAeTitle>CONQUESTSRV1</PeerAeTitle>
<Host>192.168.0.41</Host>
<Port>5678</Port>
</ConnectionParameters>
</Store>
Once these actions have been defined, the magic can be performed. The following piece of the configuration file defines how these actions will be composed into an automated workflow:
<Workflow>
<Perform action="ParseContents" onError="Hold" /> #1
<Perform action="Query" onError="Suspend" /> #2
<If field="QUERY_FOUND" value="1"> #3
<Statements>
<Perform action="Store" /> #4
</Statements>
<Else>
<Suspend resumeAction="Query" /> #5
</Else>
</If>
</Workflow>
The process is straightforward in this case:
- Extract document contents, according to previously defined ParseContents action, if nothing is found, stop processing and hold the document in queue indefinitely.
- Query worklist using retrieved values, if the query fails, suspend the job for a pre-determined amount of time, and then retry.
- If query completes successfully, and a record is found then,
- Store to PACS.
- If the query returns no records, suspend and retry the query later.
The last step helps if the timing of data in worklist (or PACS) does not precede document generation. A situation like this often arises when requisitions, which are the first documents to arrive, need to be attached to studies after they have been performed.
There are actually a multitude of variants of this workflow, sometimes involving more than one query, sometimes requiring a little bit of user input to augment the record, but the general process is a very common application of DICOM Printer 2.
We hope you too can save a few forests’ worth of trees and an FTE or two, by implementing DICOM Printer 2 in your practise.